Content Analysis
Title Analysis: Keyword Prediction
Although most of the articles have keywords with them, there are still quite a lot of articles without keywords. Meanwhile, some articles may have complicated keywords, which could also increase the difficulty of analysis. To solve this problem, we can try to predict the keywords with title analysis techniques.
In the following parts, the keyword prediction using the results from
previous keyword analysis is demonstrated. The whole workflow is shown
below:
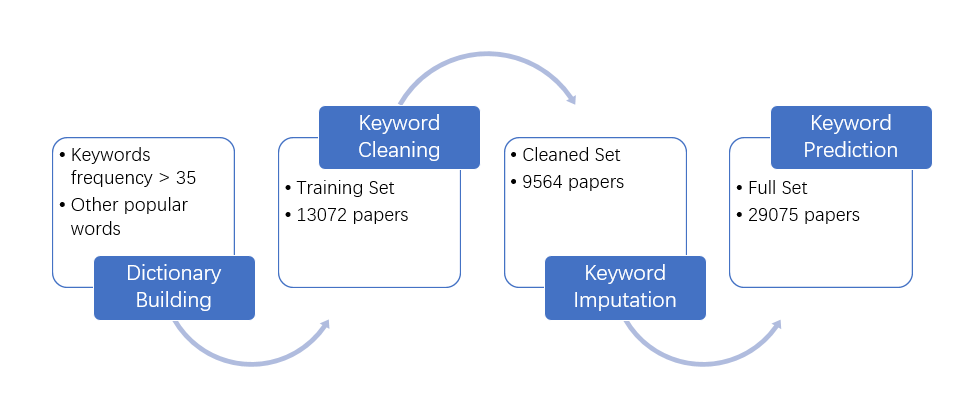
Pre-prepare: Include packages and source data
We mainly use the package quanteda for our
analysis. Quanteda is an R package for managing and analyzing textual
data. It is designed for R users needing to apply natural language
processing to texts, from documents to final analysis.
Pre-prepare: Including data and building dictonary
In our analysis, we use topic-specific dictionaries as our main method. Topic-specific dictionaries is a method somehow similar to sentiment analysis. Its aim is to determine the polarity of a text, which could be done by counting terms that were previously assigned to the given categories. With this method, we can categorize the given titles into specific keywords in our dictionary.
To use topic-specific dictionaries, the keyword corpus and dictionary
need to be built in advance. In this study, we use the results of
keywords analysis to help our dictionary construction. Our dictionary
includes all keywords with frequency larger than 35 in the keywords
analysis. In addition, some popular words, e.g. “send”, are added to the
dictionary manually to improve the performance.
Keyword Cleaning
We calculate the cleaned keyword coverage from source data first. In
this study, the keyword coverage is defined as the percent of papers
with any keyword existing after imputation. Keyword cleaning is
performed before the calculation.
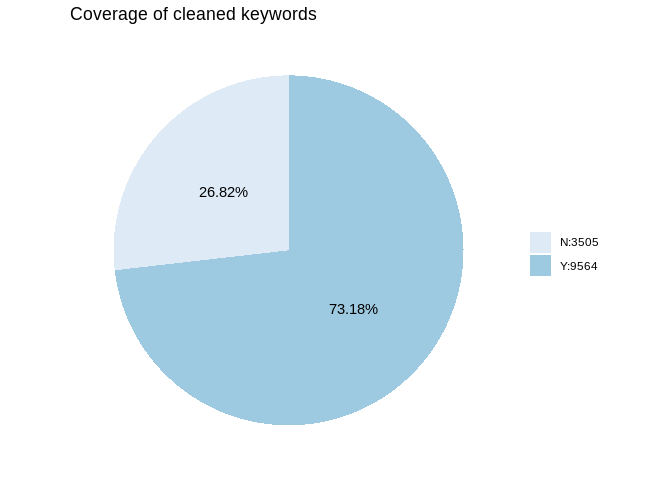 Approximately 73.18% of the papers have cleaned keyword coverage.
Approximately 73.18% of the papers have cleaned keyword coverage.
Keyword Imputation
Next, we use our dictionary to impute the keyword from the titles. In
this part, the papers with cleaned keywords are used to calculate the
correct rate of imputation. Similarly, the coverage of the imputed
keyword is calculated. Also, we calculate the accuracy of the imputation
by comparing the imputed results with cleaning results. The accuracy
here is defined as the percentage of papers where the cleaned keywords
exist in the imputed keywords for all the papers imputed.
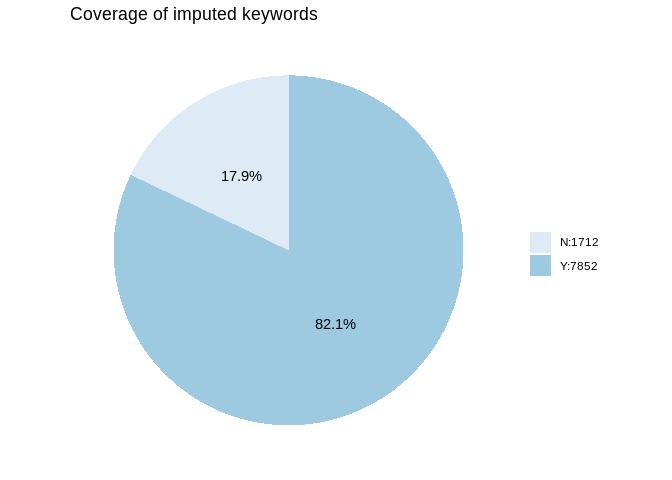
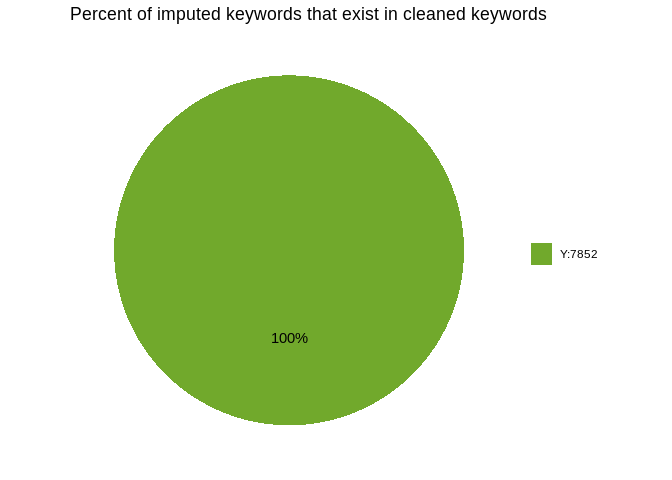
Approximately 82.1% of the papers have keyword coverage after imputation. Also, we can find that all the imputed keywords are within cleaned keywords.
Keyword Prediction
Finally, we try to use the dictionary to predict the keyword of all the
papers we collected. The coverage rate after prediction is computed.
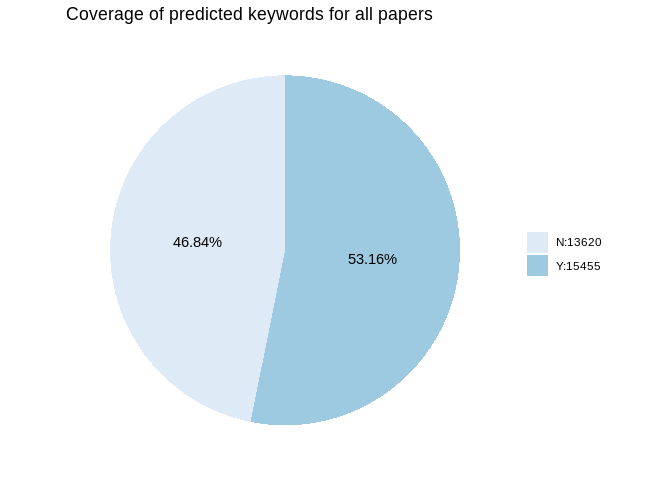 After predicting keywords using our dictionary model, the predicted
keyword coverage of all the papers is approximately 53.16%.
After predicting keywords using our dictionary model, the predicted
keyword coverage of all the papers is approximately 53.16%.
Further Explorations and conclusion
Our exploration indicates that dictionary model could be useful when
keywords are not presented. After prediction with the model, the
keywords of more than half of the papers could be imputed. Moreover, the
dictionary used in our study is relatively crude. With a better
dictionary, the coverage could be even higher.
Besides, we also tried to use Latent Dirichlet
Allocation(LDA)
to perform a topic modeling analysis. However, because of several
reasons, we did not get a satisfying result. To use the LDA method,
several topics must be pre-specified, but in our study we do not have
such topics. If we try using all the words in our dictionary as topics,
the time and resource consumption could become a big problem. Meanwhile,
even if we have our topics pre-specified, the limited length of a title
could also result in a poor accuracy in keyword prediction.
In the future, we will keep trying other methods in the title analysis, such as supervised or unsupervised learning. Furthermore, based on the current progress we’ve made, we will try to analyze the abstracts using various methods. If you are interested in our study, welcome!